UPDATE (13 December, 2016): Try the Brexit Analyzer
We have now made parts of the Brexit Analyzer available as a web service. You can try the topic detection by putting an example tweet here (choose mentions of political topics):
https://cloud.gate.ac.uk/shopfront/displayItem/sobigdata-brexit
This is a web service running on GATE Cloud, where you can find many other text analytics services, available to try for free or run on large batches of data.
We also have now a tweet collection service, should you wish to start collecting and analysing your own Brexit (or any other) tweets:
https://cloud.gate.ac.uk/shopfront/displayItem/twitter-collector
Tools Overview
It will be two weeks tomorrow since we launched the Brexit Analyser -- our real-time tweet analysis system, based on our GATE text analytics and semantic annotation tools.Back then, we were analysing on average 500,000 (yes, half a million!) tweets a day. Then, on referendum day alone, we had to analyse in real-time well over 2 million tweets. Or on average, just over 23 tweets per second! It wasn't quite so simple though, as tweet volume picked up dramatically as soon as the polls closed at 10pm and we were consistently getting around 50 tweets per second and were also being rate-limited by the Twitter API.
These are some pretty serious data volumes, as well as veracity. So how did we build the Brexit Analyser to cope?
For analysis, we are using GATE's TwitIE system, which consists of a tokenizer, normalizer, part-of-speech tagger, and a named entity recognizer. After that, we added our Leave/Remain classifier, which helps us identify a reliable sample of tweets with unambiguous stance. Next is a tweet geolocation component, which uses latitude/longitude, region, and user location metadata to geolocate tweets within the UK NUTS2 regions. We also detect key themes and topics discussed in the tweets (more than one topic/theme can be contained in each tweet), followed by topic-centric sentiment analysis.
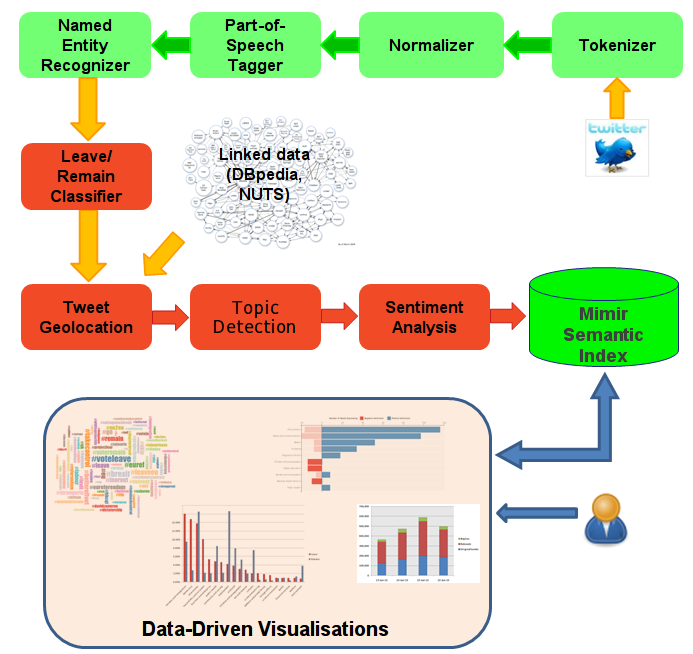
We kept the processing pipeline as simple and efficient as possible, so it can run at 100 tweets per second even on a pretty basic server.
The analysis results are fed into GATE Mimir, which indexes efficiently tweet text and all our linguistic annotations. Mimir has a powerful programming API for semantic search queries, which we use to drive different web pages with interactive visualisations. The user can choose what they want to see, based on time (e.g. most popular hashtags on 23 Jun; most talked about topics in Leave/Remain tweets on 23 Jun). Clicking on these infographics shows the actual matching tweets.
All my blog posts so far have been using screenshots of such interactively generated visualisations.
Mimir also has a more specialised graphical interface (Prospector), which I use for formulating semantic search queries and inspecting the matching data, coupled with some pre-set types of visualisations. The screen shot below shows my Mimir query for all original tweets on 23 Jun which advocate Leave. I can then inspect the most mentioned twitter users within those. (I used Prospector for my analysis of Leave/Remain voting trends on referendum day).

So how do I do my analyses
First I decide what subset of tweets I want to analyse. This is typically a Mimir query restricting by timestamp (normalized to GMT), tweet kind (original, reply, or retweet), voting intention (Leave/Remain), mentioning a specific user/hashtag/topic, written by a specific user, containing a given hashtag or a given topic (e.g. all tweets discussing taxes).
Then, once I identify this dynamically generated subset of tweets, I can analyse it with Prospector or use the visualisations which we generate via the Mimir API. These include:
- Top X most frequently mentioned words, nouns, verbs, or noun phrases
- Top X most frequent posters/frequently mentioned tweeterers
- Top X most frequent Locations, Organizatons, or Persons within those tweets
- Top X themes / sub-themes according to our topic classifier
- Frequent URLs, language of the tweets, and sentiment
How do we scale it up
It's built using GATE Cloud Paralleliser and some clever queueing, but the take away message is: we can process and index over 100 tweets per second, which allows us to cope in real time with the tweet stream we receive via the Twitter Search API, even at peak times. All of this runs on a server which cost us under £10,000.
The architecture can be scaled up further, if needed, should we get access to a Twitter feed with higher API rate limits than the standard.
Thanks to:
Dominic Rout, Ian Roberts, Mark Greenwood, Diana Maynard, and the rest of the GATE Team
Any mistakes are my own.
Any mistakes are my own.